De mi is az a normalizálás?
A csúcsszint normalizálás (peak normalization) tulajdonképpen annyit jelent, hogy megkeressük a hanganyag leghangosabb pontját, majd az egész hanganyagot addig hangosítjuk vagy halkítjuk, amíg az előbb említett leghangosabb pont akkora hangerővel nem szól, amekkorával szeretnénk.
Ha halkítunk, akkor az egész anyagot halkítjuk, ha hangosítunk, akkor is az egész anyagot hangosítjuk fel.
Vegyük egy film hangsávját példaként. A leghangosabb rész valószínűleg egy robbanás volt, melyet sikeresen le is halkítottunk, viszont a beszéd most már alig érthető, a lágy suttogás pedig gyakorlatilag hallhatatlanná vált.
Könnyen beláthatjuk tehát, hogy ez a fajta normalizálás a legtöbb esetben teljesen hasztalan lesz számunkra. Nekünk ugyanis csak a hangos részeken kell halkítanunk, a halkabb részeket pedig valamelyest felhangosítani.
Hogyan szól majd akkor egyenletes hangerővel a műsorom?
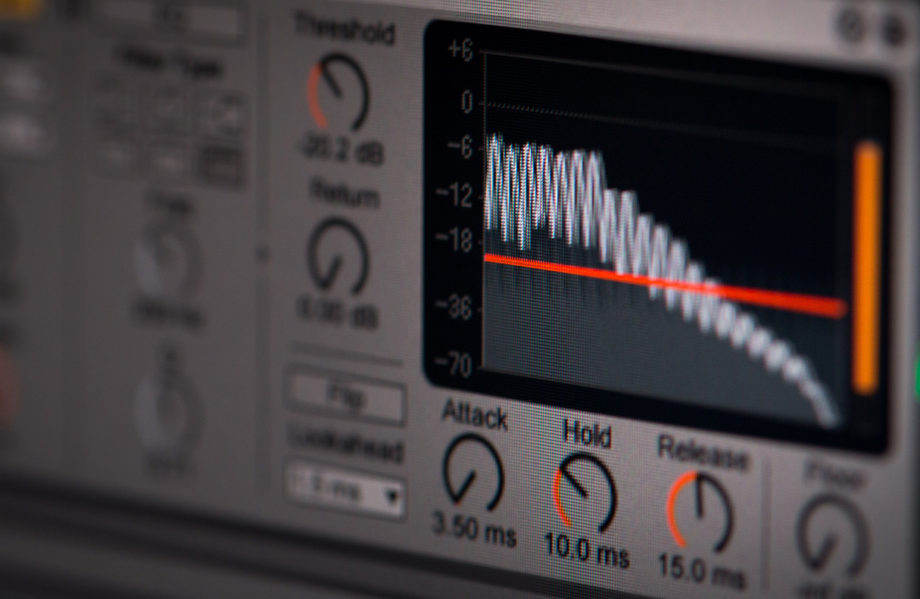
A megoldás a dinamikatartomány csökkentése, azaz a kiemelkedően hangos részeket halkabbá tenni, a kellő hangerővel szólókat meghagyni, a halk részeket pedig felhangosítani. Erre a kompresszió egy jó megoldás. Persze ezt sem szabad túlzásba vinni, hiszen az is zavaró, ha a suttogás és a kiabálás is ugyanakkora hangerővel hallható.
Ideális esetben egyébként már felvételkor megfelelő jelszintet rögzítünk, de lássuk be, egy kevéssé felkészült vendégtől nem várhatjuk el, hogy úgy használja a mikrofont, mint egy tapasztalt műsorvezető. (A hallgatók viszont meghálálják, ha időnként szólunk a vendégnek, hogy hajoljon vissza a mikrofonhoz. 😅)
A rádiós műsorgyártás élő adásokban már nagyon régóta kezeli a műsorok inkonzisztens hangosságának problémáját. Igaz, egy jó ideig inkább csak arra törekedtek az adók, hogy hangosabbak legyenek egymásnál, „véresen” komolyan viszont azóta veszik a hangosság kérdését, amióta törvény is kötelezi erre a médiaszolgáltatókat.
Európában 2010 óta minden rádió és televízió az EBU R 128 ajánlást követi. Ebben az ajánlásban bevezettek egy új mérési módot és mértékegységet a hangosság mérésére, ez volt a LUFS.
A LUFS a Loudness Units relative to Full Scale) rövidítésből ered.
A LUFS a hangerővel ellenben nem egy adott pillanat hangosságát mutatatja meg, hanem egy időintervallumét. A LUFS számítása eléggé összetett dolog, azonban a lényeg, hogy az eseti hangerőcsúcsok érdemben nem befolyásolják, illetve bizonyos idejű szüneteket és a háttérhangok egy részét sem veszi figyelembe a számítás. Szerencsére a legöbb digitális munkaállomásban van egyszerűen használható, beépített megoldás a műsor hangosságának mérésére, így nekünk nem kell ezzel különösen bajlódnunk.
Viszonyításképpen: egy TV vagy rádióműsort -23 LUFS-re gyártanak, a streaming szolgáltatók pedig általában -12 és -16 LUFS között ingestálják az anyagokat. A podcastekre nincs törvényi előírás, az egyes platformok azonban általában jelzik, hogy mi számukra az ideális.
Az általános „iparági standard” -16LUFS a podcast epizódok esetében. Nagyjából ez az a szint, ami zajosabb környezetben is érhető párbeszédet eredményez, de csendesebb környezetben sem ordít az adás. Hiszen podcastet szinte mindenhol hallgatunk. Más a háttérzaj szintje autóban, buszon, vonaton, repülőgépen és nyilván más az otthon magányában is.
Érdemes minden podcast epizódot azonos hangosságúra gyártani, hiszen a rossz hangminőség vagy az ingadozó hangerő „elkapcsolási faktor” a hallgatóknál. Aki pedig később csatlakozik a műsorunkhoz, az nagyon hálás lesz, ha több epizódon át nem kell a hangerő gombhoz nyúlnia.
Már meglévő anyagok hangosságát is érdemes utólag egy szintre hozni. Ez tulajdonéppen egy ingest folyamat, ilyenkor a műsor hossza vagy tartalma nem változik, csak a hangosságot kezeljük.
Az általunk készített podcast epizódokat (hacsak nincs más kérés) -16 LUFS ( -19 LUFS mono 🙂) hangosságra gyártjuk.